
Build an app idea generator with Rails and Nokogiri
23 Sep 2019 - John
I was trying to come up with an idea for an app until I thought "I wish there was an app that gave you to APIs to mash for a new app," and that there was my new app idea. I was well aware of some lists of public APIs, but I wanted something more random. I wanted something that gave me a random pair for me to see if they’re a good match for a new app. On the other hand, I was always curious about Nokogiri, so I set up this small project to try it out. Click here to download the complete project or here for a deployed demo.
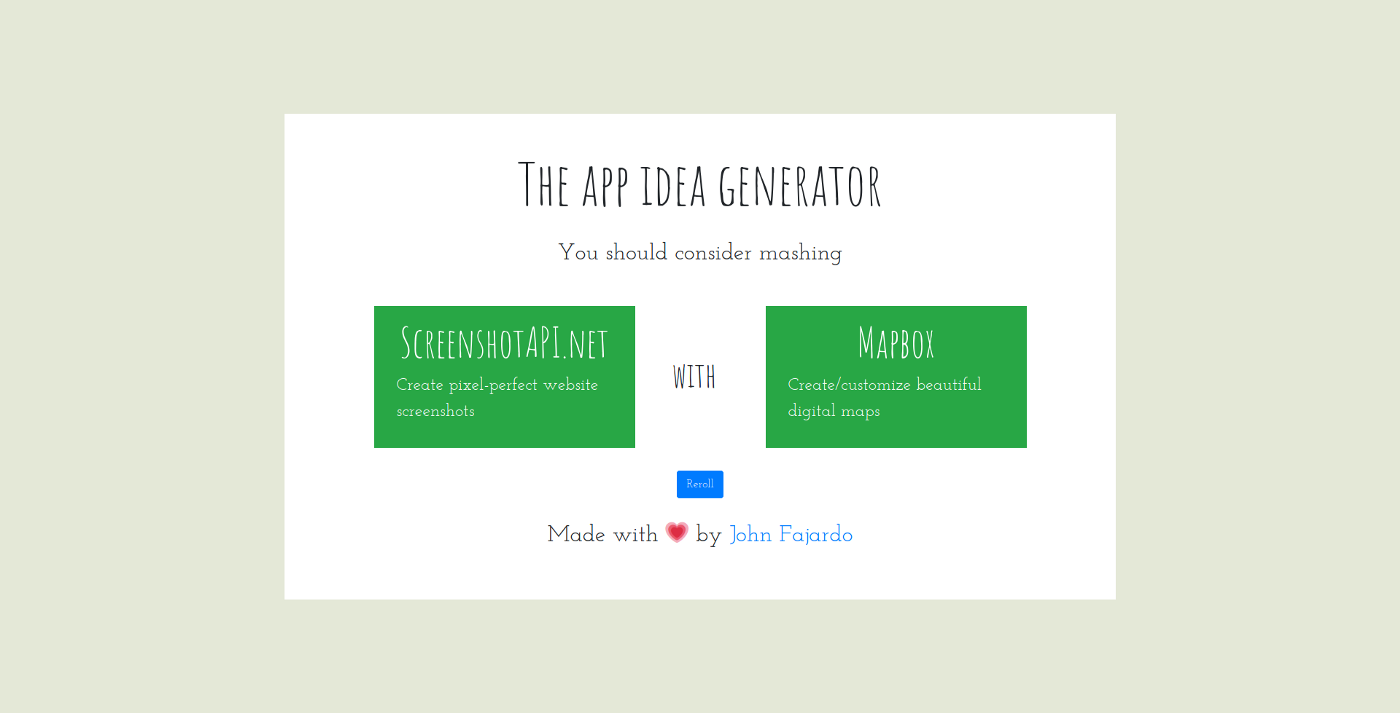
This project is pretty simple. It basically scrapes a list of public APIs to store them in the database at seed time, and then it’s just a matter of a single route that takes two of them for us to determine if they’re an useful match, so the bulk of this project lies on the seeds file.
Step 1: Build your rails app
We start the app by running rails new app-idea-generator -d postgresql. You can drop the postgresql switch and just default to SQLite3 if you just want to work locally and don’t intend to deploy to Heroku.
Then open your Gemfile and add the following lines at the end:
gem 'httparty'
gem 'nokogiri'
gem 'bootstrap'
and then run bundle install.Step 2: The database structure
We’re going to scrape our data from this page. If you see the table for each category:
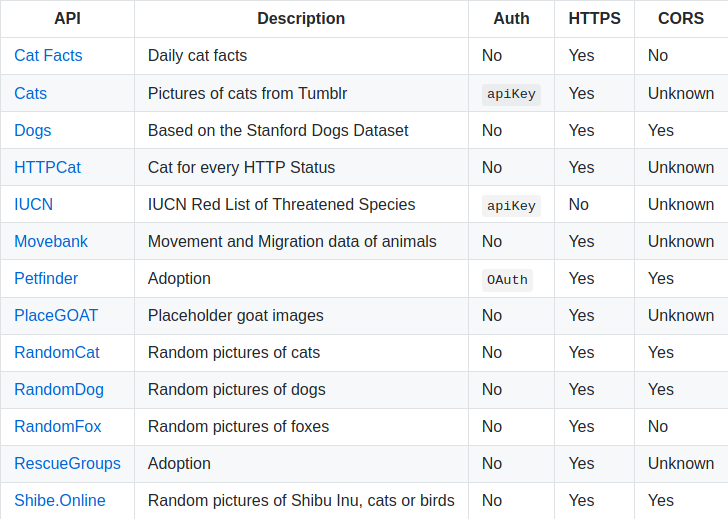
You can see that we have a name, a description and whether or not it uses auth, https and CORS. We also have a master list of categories at the top:

We’re going to model our database after this structure. So go back to your terminal and create your first model:
rails g model Category name:stringThis is where we’re keeping our master list of categories. Since we won’t need the links, we’re just going to store the names.
Next we need the table to hold our APIs:
rails g model Api name:string description:text auth:string https:text cors:string url:text category_id:integerNow open /app/models/api.rb file and set a belongs to association to Category:
belongs_to :categoryAnd then set a has many in /app/models/category.rb:
has_many :apisThen run your migrations with rails db:migrate, but remember to use rails db:create first if you’re using postgres.
Now it’s time to set up our route. Open the /config/routes.rb and change it like this:
Rails.application.routes.draw do
get '/', to: 'apis#index'
root 'apis#index'
endThen finally, create the only controller we’re going to need:
rails g controller Apis indexThen inside the index definition on /app/controllers/apis_controller , define the index action:
@apis = Api.all.sample(2)This is all we’re going to need. We’re basically doing a SELECT * FROM 'apis' and then choosing two rows at random. we’re going to use this result later in our views, but first, let’s take care of the main reason for this project: the seeds file.
Building our seeds file
We start our scraper by first defining the page we want to scrape:
url = "https://github.com/public-apis/public-apis"and then giving the url to HTTParty for it to retrieve, give it to Nokogiri and store in a variable:
parsed_page = Nokogiri::HTML(HTTParty.get(url))At this point, we have the full contents of the page and we can access it through the parsed_page variable. Let’s get our categories first.
With Nokogiri, we have the ability to specify the XML path of an element (its XPath) to read its contents. If you inspect the list:
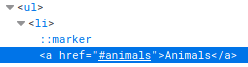
The first element of our listyou can see that the list is a regular ul, and what we want is the text of each a tag, which in turn is inside an li item, so we need to target the text of EACH a that is inside every li of our ul.
Sounds confusing, but let’s build it so it’s more clear. Right click on one of the a tags in your inspector and click on copy > Copy full XPath if you’re on Chrome or copy > XPath if you’re on Firefox.
Now if you paste the contents of your clipboard, you’ll end up with something like this:
/html/body/div[4]/div/main/div[2]/div/div[5]/div[3]/article/ul/li[1]/aThe exact index of each div past the second one will vary so let’s get rid of them:
/html/body/div[4]/div/main/div[2]/div/div/div/article/ul/li/aNow let’s plug this into Nokogiri and store it as a variable:
categories = parsed_page.xpath('/html/body/div[4]/div/main/div[2]/div/div/div/article/ul/li/a')This will give us an array of objects, and each one has a property called text , which is what we’re after. So now it’s just a matter of saving the text property of EACH object to our database:
categories.each do |cat|
Category.create(name: cat.text)
endIf you run rails db:seed and check your database, you can see the list of categories already populated:
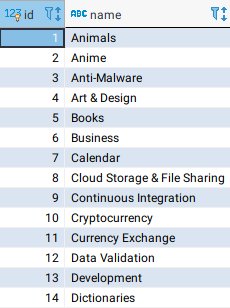
Only showing 14, but there should be 45
Remember to drop your database and then create and run your migrations again if you do this, or else you’ll end up with duplicate categories.
Now let’s get our tables. Similarly to the way we got our categories list, we need to get the XPath of our tables and feed it to Nokogiri. We also need an empty array to store our rows, which we will ultimately insert into the database:
tables = parsed_page.xpath('/html/body/div[4]/div/main/div[2]/div/div/div/article/table')
rows = []Theoretically, we could just get away with using a simple .each on our categories list, but we have a problem: arrays start from 0, but the id’s in the database start from 1, so let’s use each_with_index and use the index to select each table’s tbody, and then each cell of the table. We specify the tbody because if we didn’t, we would be also targeting the header, which we don’t need:
categories.each_with_index do |cat, index|
tables[index].search('tbody tr').each do |tr|
cells = tr.search('td')
link = ''
values = []
row = {
'name' => '',
'description' => '',
'auth' => '',
'https' => '',
'cors' => '',
'category_id' => '',
'url' => ''
}
end
endFinally, we target every ROW of our table. Each row will become a record on our database, so we need to build them properly. We start doing so by creating an empty string called link where’re going to store the urls, then an empty array called values where we’re going to store the rest of the values and finally, a hash where we’ll store the rest of the values.
To get the links, we’re going to use Nokogiri’s css method to target every a tag it finds, and then grab the value of their ['href'] index and save it into our link variable:
cells.css('a').each do |a|
link += a['href']
endThen we need to do the same with the rest of the fields. To do so, we again go through each cell and push their contents into our values array:
cells.each do |cell|
values << cell.text
endOur array also needs the category_id of each row, and as you already know, the index variable is exactly what we need, except it starts from 0, so we need to add 1 to it and push it to our values array. While we’re at it, let’s also add the link to our values array:
values << index+1
values << linkWe finally have a fully formed array that we can use to populate the values of our hash and send the hash to our rows array:
rows << row.keys.zip(values).to_hWith this, we have a huge array of objects in our main rows array. Each object is going to become a record in the database, so a simple foreach is all we need to insert them:
rows.each do |row|
Api.create(row)
endFor reference, this is what the full seeds file should look like:
# This is the page we're scraping
url = "https://github.com/public-apis/public-apis"
# And this is where we're storing the pageparsed_page = Nokogiri::HTML(HTTParty.get(url))
# Get categories from the ul at the topcategories = parsed_page.xpath('/html/body/div[4]/div/main/div[2]/div/div/div/article/ul/li/a')
categories.each do |cat|
Category.create(name: cat.text)
end
# Get all tables from the page
tables = parsed_page.xpath('/html/body/div[4]/div/main/div[2]/div/div/div/article/table')
rows = []
categories.each_with_index do |cat, index|
tables[index].search('tbody tr').each do |tr|
cells = tr.search('td')
link = ''
values = []
row = {
'name' => '',
'description' => '',
'auth' => '',
'https' => '',
'cors' => '',
'category_id' => '',
'url' => ''
}
cells.css('a').each do |a|
link += a['href']
end
cells.each do |cell|
values << cell.text
end
values << index+1
values << link
rows << row.keys.zip(values).to_h
end
end
rows.each do |row|
Api.create(row)
endIf you check your database after running rails db:seed, you will see something like this:
With this, the bulk of our app is done! All we need to do now is build a simple view:
<div class="vertical-center">
<div class="container p-5">
<h1 class="text-center main-title">The app idea generator</h1>
<p class="text-center mt-4">You should consider mashing</p>
<div class="row justify-content-center mt-5">
<div class="col-4 bg-success d-flex">
<div class="justify-content-center align-self-center px-3 py-3">
<h2><a class="text-white text-center block" href="<%= @apis[0].url %>"><%= @apis[0].name %></a></h2>
<p class="description"><%= @apis[0].description %></p>
</div>
</div>
<div class="col-2 d-flex">
<div class="justify-content-center align-self-center text-center">
<h3 class="ml-4">with</h3>
</div>
</div>
<div class="col-4 bg-success d-flex">
<div class="justify-content-center align-self-center px-3 py-3">
<h2><a class="text-white text-center block" href="<%= @apis[1].url %>"><%= @apis[1].name %></a></h2>
<p class="description"><%= @apis[1].description %></p>
</div>
</div>
</div>
<p class="text-center mt-4"><button class="btn btn-primary" onClick="window.location.reload();">Reroll</button></p>
<p class="footnote text-center mt-4">Made with 💗 by <a href="https://johnfajardo.dev">John Fajardo</a></p>
</div>
</div>And then add the following to the head section of your /app/views/layouts/application.html.erb:
<link href="https://fonts.googleapis.com/css2?family=Amatic+SC:wght@400;700&family=Josefin+Slab&display=swap" rel="stylesheet">Then to use Bootstrap, rename your /app/assets/stylesheets/application.css to /app/assets/stylesheets/application.scss and add the following to it:
$new-bg : #e4e8d7;
$body-bg: $new-bg;
.vertical-center {
min-height: 100%;
min-height: 100vh;
display: flex;
align-items: center;
}
.container {
background-color: #fff;
margin-top: auto;
margin-bottom: auto;
.row{
overflow: hidden;
}
[class*="col-"]{
margin-bottom: -99999px;
padding-bottom: 99999px;
}
.main-title {
font-family: 'Amatic SC', cursive;
font-size:5em;
}
h2 {
font-family: 'Amatic SC', cursive;
font-size:3.5em;
}
h3 {
font-family: 'Amatic SC', cursive;
font-size:3em;
display: block;
width: 100%;
}
p {
font-family: 'Josefin Slab', serif;
font-size: 2em;
}
.description {
color: #fff;
font-size: 1.5em;
}
.block {
display: block;
margin: 0 auto;
}
.footnote {
font-size: 2em;
}
}
@import "bootstrap";And that’s it! Now you have no excuse to come up with new -and weird- apps!
Room for growth? Sure!
Our app is very simple, but that doesn’t mean we can’t keep where we can improve things.
- While our apis table is relatively small, with 641 rows at the time of this writing, it’s no big deal, but we’re currently selecting our two random rows by fetching ALL of them first and then grabbing two of them at random. What if a couple of years from now, the github repo we scraped grows to 10,000+ records?
- We should strive to NEVER select all records. One way we could solve this is creating two random numbers with a ceiling equal to the total amount of rows in the database, then comparing them for uniqueness. If they’re the same, we generate another number, and if they’re not, we proceed to select only those two records by id using our unique numbers. That way we don’t grab the whole thing before making a choice.
So there you have it, now go make some weird app!